GENialOMICS

| Weekly Group Assignments | Shared Group Journals | Project Links | Team Members |
|---|---|---|---|
|
|
|
|
|
Contents
Week 10
- On November 3, 2015, GÉNialOMICS chose to create database for Burkholderia cenocepacia.
- On November 5, 2015, a journal detailing the complete genome of Burkholderia cenocepacia (strain J2315) titled The Genome of Burkholderia cenocepacia J2315, an Epidemic Pathogen of Cystic Fibrosis Patients was found.
Week 11
Individual Goals and Progress
| Weekly Goals and Progress | ||||||||
|---|---|---|---|---|---|---|---|---|
| Anu Varshneya | Brandon Litvak | Veronica Pacheco | Kevin Wyllie | |||||
| Goals |
|
|
Work with Kevin Wyllie
|
Work with Veronica Pacheco
| ||||
| Progress |
|
|
|
Created methods diagram (media:KWVPMethoddiagram.jpg).
| ||||
| Individual Journal Pages | ||||||||
{kind=link}
File Management System
- Files utilized in weekly projects will renamed as follows: XXXX_GEN_(Initials)(Week#)_yyyymmdd, where "XXXX" is the original filename. If multiple versions of the same file (with identical filenames) are used on the same day then a (positive integer) (starting from 1) will be added to any additional versions (e.g. XXXX_GEN_BL11_yyyymmdd, XXXX_GEN_BL11_yyyymmdd(1), XXXX_GEN_BL11_yyyymmdd(2), for three different versions of the same file uploaded by Brandon Litvak during Week 11)
- Files will be uploaded to the weekly progress table under a file row with a clear label (under the respective group member that created them/used them)
- All original unmodified files will be saved and will also be uploaded, together, as a compressed zip with the filename: ORIG_GEN_(Initials)(Week#); the compressed zip containing all original files will be the last entry in the row designated for the files, with the label "ORIGINAL FILES"
Other Progress
- A journal using the B. cenocepacia genome in a microarray experiment titled Biofilm-Grown Burkholderia cepacia Complex Cells Survive Antibiotic Treatment by Avoiding Production of Reactive Oxygen Species was approved for analysis.
Journal Club Presentations
Genome Paper Presentation Week 11
Microarray Paper Presentation Week 12
Week 12
Individual Goals and Progress
| Weekly Goals and Progress | ||||||||
|---|---|---|---|---|---|---|---|---|
| Anu Varshneya | Brandon Litvak | Veronica Pacheco | Kevin Wyllie | |||||
| Goals |
|
|
Work with Kevin Wyllie
|
Work with Veronica Pacheco
| ||||
| Progress |
|
|
|
| ||||
| Individual Journal Pages | ||||||||
| Files Used/Created | ||||||||
Other Progress
Week 14
Individual Goals and Progress
| Weekly Goals and Progress | ||||||||
|---|---|---|---|---|---|---|---|---|
| Anu Varshneya | Brandon Litvak | Veronica Pacheco | Kevin Wyllie | |||||
| Goals |
|
|
Work with Kevin Wyllie
Create a .mapp file showing one pathway that is changed in your data. |
Work with Veronica Pacheco
Create a .mapp file showing one pathway that is changed in your data. | ||||
| Progress |
|
|
Work with Kevin Wyllie
|
Work with Veronica Pacheco
| ||||
| Individual Journal Pages | ||||||||
| Files Used/Created |
Build 2 - with customized species profile: Anuvarsh (talk) 15:22, 1 December 2015 (PST) Anuvarsh (talk) 14:58, 3 December 2015 (PST) |
see Kevin's section --> | ||||||
Other Progress
Reflections
Anu Varshneya
- What worked?
- In general, I think our group worked very well together! I think we are all motivated to get this project done well, and are communicating well with each other regarding our progress.
- What didn't work?
- I think for the most part we did a great job. I think the only ideas I have moving forward is a little bit more planning in regards to how we plan to attack the writing and presentation portion of the project. I am not concerned about us getting it done on time and with good quality, just that we create a plan of attack soon so that everyone is on the same page. :)
- What will I do next to fix what didn't work?
- Though nothing has not worked, I think we will just talk tomorrow about how we want to approach the writing and the presentation and set up some group work times.
Kevin Wyllie
- What worked?
- Our initial GenMAPP import worked! 284 errors, which, out of 7251, does sound so bad to me!
- What didn't work?
- Maybe this isn't actually an example of something not working, but our calculated fold changes were quite different (much lower in magnitude) from those reported in Van Acker et al's paper. However, they had the same directions and generally saw the same relative trends (ie the relatively higher fold changes in the paper were among the higher in our data). Also, very few of the genes they considered significant (with their super-lenient criteria that results in 30% of the genes seeing significant changes) were significant by our criteria.
- What will I do next to fix what didn't work?
- We just need to triple/quadruple check that our data processing protocol is legitimate. Other than that, there's not much we can do in terms of fold changes. And for statistical significance, we potentially should reconsider heightening our BH P-value threshold above 0.05, as currently we're only considering about 8% of the genes to see a significant change. But maybe this is not too low of a number.
Veronica Pacheco
- What worked?
- Right off the bat, our first run through GenMAPP worked. As expected, there were exceptions and it generated an EX.txt file. There were 284 errors. We then handed over the file to Brandon so we shall see if the number of errors can decrease.
- What didn't work?
- What we initially thought didn't work or didn't seem correct was that fact that our values for fold changes were much smaller than the values reported in Van Acker et al's paper. The direction, for the majority, aligned with what was reported however the concrete values had large differences.
- What will I do next to fix what didn't work?
- Initially, we went to make sure our methods were correct. We traced back our steps and made sure the calculations were done correctly.After we double checked, we then sought help from Dr. Dahlquist and Dr. Dionisio. From their response, it seems we should go over it one more time and if there is no source of error on our part, we continue the project with our fold changes.
Brandon Litvak
- What worked?
- I think a lot of things worked this week. Team work and communication was a great help in getting the bulk of this week's work done. The initial exported database was not working as planned and, as a team, we discovered that the reason had to do with the fact that GenMAPP builder was utilizing the wrong type of gene name; this knowledge allowed us to create builds this week that happened to work fairly well. These new builds covered the gene names of interest and led to a relatively small amount errors in GenMAPP. I think that, above all, the thing that worked best this week was my team. We were able to communicate and collaborate very well.
- What didn't work?
- At the present moment, I can't really think of things that really did not work. With respect to the gene database project for J2315, everything appears to be on track; I would say that the major problems that were encountered in Week 14 were resolved. I feel that all of the major work for the project is complete; all that remains, is to synthesize the work done in a paper and presentation. As a group, we did get little work done on the final deliverables (which should be the focus, for this week) but we did get a lot of valuable work done for the project. We haven't managed to plan much regarding the final deliverables, either (but this is a minor issue).
- What will I do next to fix what didn't work?
- We will need to meet as a group and discuss the state of the project. I personally feel really good about the work so far and it would be helpful to hear, with the bulk of the work done, how everyone else feels. Additionally, I think that we will need to plan out our approach for the final project as soon as possible. Once we have discussed the project and made a plan, I think that we should set aside some time to work on the group project, as a team. I will check in with the group members on Tuesday, share my major findings for the week, and discuss future courses of action (regarding the last bits of the project).
Week 15
Individual Goals and Progress
| Weekly Goals and Progress | ||||||||
|---|---|---|---|---|---|---|---|---|
| Anu Varshneya | Brandon Litvak | Veronica Pacheco | Kevin Wyllie | |||||
| Goals |
|
|
Work with Kevin Wyllie
|
Work with Veronica Pacheco
| ||||
| Progress |
|
|
|
| ||||
| Individual Journal Pages | ||||||||
| Files Used/Created |
| |||||||
Other Progress
- On December 14, 2015, GENialOMICS completed a presentation summarizing their methods and findings.
Deliverables
Burkholderia cenocepacia Genome Paper
Holden, M. T. G., Seth-Smith, H. M. B., Crossman, L. C., Sebaihia, M., Bentley, S. D., Cerdeño-Tárraga, A. M., … Parkhill, J. (2009). The Genome of Burkholderia cenocepacia J2315, an Epidemic Pathogen of Cystic Fibrosis Patients . Journal of Bacteriology, 191(1), 261–277. http://doi.org/10.1128/JB.01230-08
- The link to the abstract from PubMed. [1]
- The link to the full text of the article in PubMedCentral. [2]
- The link to the full text of the article (HTML format) from the publisher web site. [3]
- The link to the full PDF version of the article from the publisher web site. [4]
- Who owns the rights to the article? American Society for Microbiology
- Does the journal own the copyright? Yes
- Do the authors own the copyright? No
- Do the authors own the rights under a Creative Commons license? No
- Is the article available “Open Access”? Yes
- What organization is the publisher of the article? What type of organization is it? (commercial, for-profit publisher, scientific society, respected open access organization like Public Library of Science or BioMedCentral, or predatory open access organization, see the list of) (Open Access Scholarly Publishers Association Members) here. American Society for Microbiology which is a scientific society
- Is this article available in print or online only? It is both available in print and online.
- Has LMU paid a subscription or other fee for your access to this article? Well I first looked at this article through web of science which LMU does pay for but looking at the article through PubMed, PubMed central and the publisher website was free.
- How many articles does this article cite? It has 150 cited references.
- How many articles cite this article? It is cited 128 times.
- Based on the titles and abstracts of the papers, what type of research directions have been taken now that the genome for that organism has been sequenced? A lot of the papers revolved around antibiotic resistance and therapeutic strategies.
Microarray Paper
Van Acker, H., Sass, A., Bazzini, S., De Roy, K., Udine, C., Messiaen, T., ... & Coenye, T. (2013). Biofilm-grown Burkholderia cepacia complex cells survive antibiotic treatment by avoiding production of reactive oxygen species. PLoS One, 8(3), e58943.
- This article is suitable for your project. — Kdahlquist (talk) 10:17, 10 November 2015 (PST)
- The link to the abstract from PubMed: http://www.ncbi.nlm.nih.gov/pubmed/?term=Biofilm-Grown+Burkholderia+cepacia+Complex+Cells+Survive+Antibiotic+Treatment+by+Avoiding+Production+of+Reactive+Oxygen+Species
- The link to the full text of the article in PubMedCentral: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3596321/
- The link to the full text of the article (HTML format) from the publisher web site: http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0058943
- Cannot find HTML format on publisher web site.
- The link to the full PDF version of the article from the publisher web site: http://www.plosone.org/article/fetchObject.action?uri=info:doi/10.1371/journal.pone.0058943&representation=PDF
- Who owns the rights to the article? Authors of the article: Heleen Van Acker, Andrea Sass, Silvia Bazzini, Karen De Roy, Claudia Udine, Thomas Messiaen, Giovanna Riccardi, Nico Boon, Hans J. Nelis, Eshwar Mahenthiralingam, Tom Coenye
- Does the journal own the copyright? Yes.
- Do the authors own the copyright? No.
- Do the authors own the rights under a Creative Commons license? Yes.
- Is the article available “Open Access”? Yes.
- What organization is the publisher of the article? What type of organization is it? Public Library of Science, Professional OA Publisher, Member of Open Access Scholarly Publishers Association
- Is this article available in print or online only? Available in print and online.
- Has LMU paid a subscription or other fee for your access to this article? No.
- Where does MicroArray Data reside? https://www.ebi.ac.uk/arrayexpress/experiments/E-MEXP-3532/?keywords=&organism=Burkholderia+cenocepacia&exptype%5B%5D=%22rna+assay%22&exptype%5B%5D=%22array+assay%22&array=
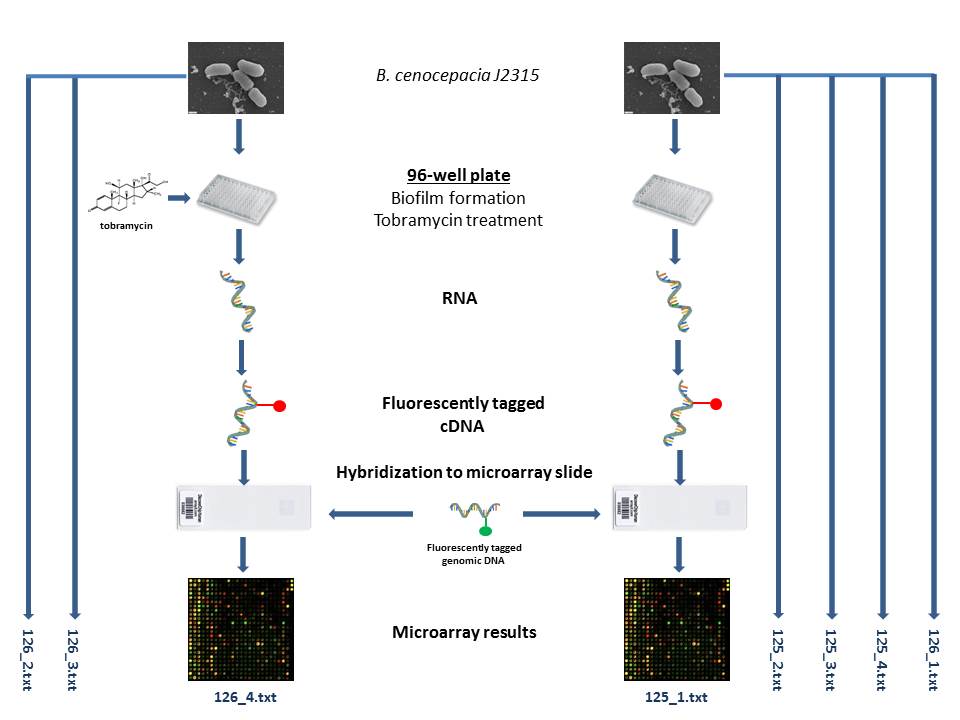
- What experiment was performed? What was the "treatment" and what was the "control" in the experiment? The experiment hoped to test whether persister cells are present in Burkholderia cepacia complex (Bcc) biofilms, what the molecular basis of antimicrobial tolerance in Bcc persisters is, and how persisters can be eradicated from Bcc biofilms. Burkholderia cenocepacia biofilms were treated with 1024 µg/ml of tobramycin in the treatment group. The control group did not receive any tobramycin.
- Were replicate experiments of the "treatment" and "control" conditions conducted? Were these biological or technical replicates? How many of each? 2 technical replicates were made across 5 biological replicates for the control, and 2 technical replicates of 3 biological replicates of the treatments.
- How many articles does this article cite? This article has 34 cited references.
- How many articles cite this article? This article is cited 17 times in All Databases, and 17 time in Web of Science Core Collection.
- Based on the titles and abstracts of the papers, what type of research directions have been taken now that the genome for that organism has been sequenced? Most of the articles are related to antimicrobial therapy, tolerance, and resistance.